dbt Integration
Overview
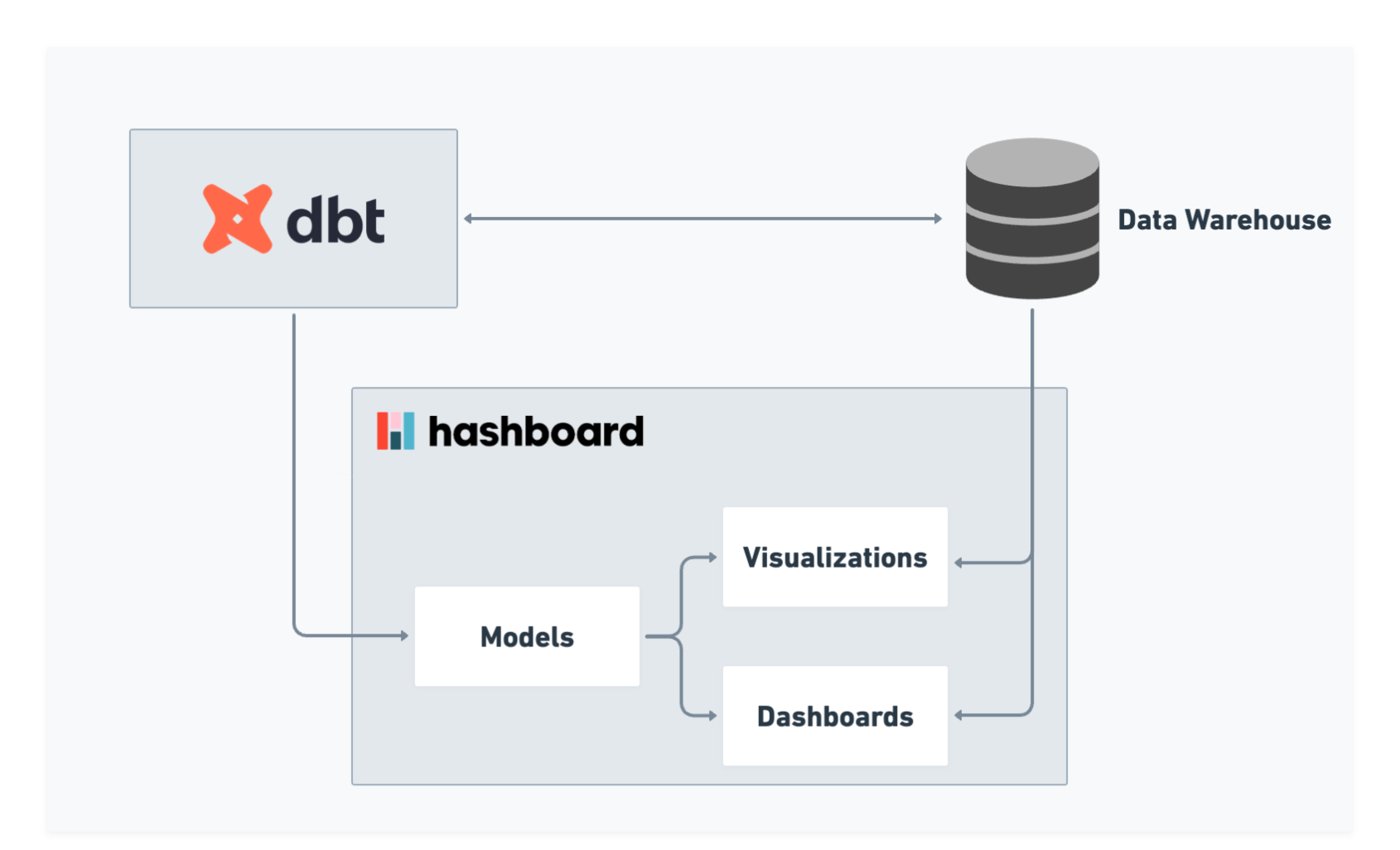
Hashboard can import models directly from dbt by specifying measures in your dbt yaml file. Hashboard will automatically sync dbt documentation and keep measures in sync with downstream dashboards (whether they are checked into version control or not). The Hashboard dbt integration can also be integrated in CI/CD workflows.
Configure your .hbproject file
If you have not already, configure the root of your Hashboard project and your dbt project with hb init.
Set the dbtRoot key in your Hashboard project file using hb init --dbt-root=path/to/dbt/project or manually editing the .hbproject file if it already exists.
# This file marks the root of your Hashboard project directory. It determines
# the identity of the resources in your local filesystem
# and encodes additional project configuration metadata.
# For additional information please visit docs.hashboard.com.
dbtRoot: ./dbt/Configure your dbt_project.yml
You can use the hashboard-defaults key to specify the hashboard version and the data connection to use.
models:
+meta:
# hashboard-defaults settings will be merged into each Hashboard model
hashboard-defaults:
hbVersion: "1.0"
source:
connectionName: snowflake_production # which Hashboard data connection to useDefine model information
Hashboard will build any dbt model that has a hashboard meta key present. The simplest example of a Hashboard model just defines a measure. Attributes are inherited automatically.
version: 2
models:
- name: order_attribution
description: This model describes how each order is attributed to different marketing touchpoints.
columns:
- name: attribution_id
description: Unique ID for the attribution.
- name: order_id
description: Order ID, matches the order_id in the sales model.
- name: touchpoint_id
description: ID of the marketing touchpoint which led to the order.
meta:
hashboard:
cols:
- id: row_count
type: measure
name: Order Attribution Records
aggregate: row_countBuild your Hashboard models
Assuming you've set the dbtRoot flag with hb init, you can simply run hb build and Hashboard will automatically include your dbt-specified Hashboard models.
hb buildSlim CI: Defer schema with dbt Cloud or Core
The Hashboard dbt integrations support Defer for both dbt Core and Cloud when running a build, also commonly referred to as "Slim CI".
Learn more about how dbt Defer in Core (opens in a new tab) or dbt Defer in Cloud (opens in a new tab) can speed up development and reduce costs.
Setup for database deferrals
To enable database deferrals update your .hbproject file to include a dbtOptions key with the following configuration:
# This file marks the root of your Hashboard project directory. It determines
# the identity of the resources in your local filesystem
# and encodes additional project configuration metadata.
# For additional information please visit docs.hashboard.com.
dbtRoot: ./dbt/
dbtOptions:
useDefer: trueIf you're deferring across databases and not just schemas you must also set the includeDbNameInSchema value so that Hashboard fully qualifies the tables being referenced by your models. Also ensure that the data source connection you have configured for your dbt models has access to both production and development databases.
# This file marks the root of your Hashboard project directory. It determines
# the identity of the resources in your local filesystem
# and encodes additional project configuration metadata.
# For additional information please visit docs.hashboard.com.
dbtRoot: ./dbt/
dbtOptions:
useDefer: true
includeDbNameInSchema: trueThese settings can be overridden on a per-command basis by specifying the environment variables HB_DBT_USE_DEFER=true/false and HB_DBT_INCLUDE_DB_IN_SCHEMA=true/false respectively.
dbt Core
When using dbt Core, you can use the --dbt-state flag to pass a state for deferral.
hb build --dbt-state=target_prod/dbt Cloud
With dbt Cloud, the Hashboard CLI will infer deferred schemas without any additional flags. You can simply run hb build once you've configured your Hashboard project file.
hb buildWhat dbt commands are run as part of hb build?
The Hashboard CLI runs dbt commands internally to gather metadata about the current state of your dbt project. The Hashboard CLI never executes dbt run or dbt build to create content in your database on your behalf. In most cases, you will execute dbt run on your own, then execute hb build afterwards.
The Hashboard CLI currently invokes the following commands:
dbt lsis used to select the targeted models for the build.- For each selected model,
dbt compileis run to determine the fully qualified reference to where the model would be built in the warehouse, including the deferred schema. dbt parseis run to generate the dbtmanifest.json, which contains the Hashboard model definitions.
If you specify hb --verbose build then all internal dbt commands and their outputs will be logged to the console.
If your dbt setup requires additional options that the CLI is unaware of, you can specify them as DBT environment variables (for a full list of flag and environment variable substitutes please refer to the dbt flag documentation (opens in a new tab)). Alternatively, set the HB_DBT_FLAGS environment variable to pass a single string of additional flags/arguments through to all wrapped DBT invocations.
Building a subset of models with dbt: args
By default, hb build will create a Hashboard build that includes all of the Hashboard models specified in dbt as well as any other Hashboard resources present in the working directory.
If you only want to build a subset of the models, you can use dbt's select syntax (opens in a new tab) prefixed by dbt: .
For example, if you only wanted to build modified dbt models, you could run
hb build dbt:state:modifiedIf you only wanted to build dbt models without rebuilding resources defined in Hashboard yaml files you could run
hb build dbt:allModel specification
The hashboard-defaults connection configuration in the example above gets merged into the Hashboard configuration inside each dbt model. If you don't specify the defaults, you must add the complete connection information in the meta key of each dbt model you want imported to Hashboard. Only dbt models that specify a hashboard key will get built into Hashboard models.
version: 2
models:
- name: a_model
description: model docs here
meta:
hashboard:
hbVersion: "1.0" # Hashboard dbt integration version
source:
connectionName: snowflake_production # which Hashboard data connection to use, can also be specified globally if you use hashboard-defaults
columns:
- name: a_str
description: some column documentation
# ... your dbt columnsSome notes on how models get built from dbt:
- Hashboard will read the dbt manifest file and find all models with a
hashboardkey specified within themetakey. - The name of dbt model is imported into Hashboard as the model name (this can be overriden).
- Columns specified explicitly in the dbt model will become attributes in Hashboard.
- Descriptions on the model will get imported as model documentation.
- You can specify additional attribute configuration in a
metakey for a column.
How data model source is determined:
sourcehas the same options as the corresponding field of Hashboard data models.- Unless otherwise specified, Hashboard automatically infers defaults for the source
physicalNameandschema. If noconnectionNameorconnectionIdis specified, Hashboard will try to use a connection whose name is the same as the dbt target database (e.g."bigquery"or"snowflake").
Hashboard will include each dbt column as an attribute in the corresponding Hashboard model. You can also add additional fields to the dbt columns to take advantage of Hashboard's more advanced modeling features:
# ... as above
columns:
- name: my_dbt_attribute
documentation: this is a dbt attribute
tests:
- unique
- not_null
# add additional configuration to this column
meta:
hashboard:
primaryKey: trueTo add Hashboard measures (or other attributes not present in the dbt model) to the imported model, you can add a cols field to the dbt model's meta.hashboard configuration:
models:
- # ... dbt schema configuration, as above
meta:
hashboard:
cols:
- id: daily_active_users
type: measure
name: Daily Active Users
sql: COUNT(DISTINCT customer_id) / COUNT(DISTINCT create_at)Hashboard configuration in your dbt schema file has access to the same templating and macros (opens in a new tab) as your dbt configuration. You could, for example, configure the Hashboard data connection based on your dbt target:
models:
- # ... dbt model configuration
meta:
hashboard:
hbVersion: "1.0"
name: "customers"
source:
# configure the source based on the dbt target
connectionName: "{{ target.database }}"Column descriptions will be automatically synced from dbt to the corresponding Hashboard model during deploys.
Global configuration
If all models use the same Hashboard source, you can configure a default source in the dbt_project.yml file:
models:
the_models:
+meta: # will be applied to every model in models/the_models
hashboard-defaults:
source:
connectionName: snowflake_production # which Hashboard data connection to useTo import all dbt models in a folder as Hashboard models, simply add
models:
folder:
+meta:
hashboard:
hbVersion: "1.0"
source:
connectionName: snowflake_production # which Hashboard data connection to useThis configuration will add the meta.hashboard object to every model in folder, so they will all be imported into Hashboard. You can still add additional metadata for the specific models (such as adding additional metrics).